
TLDR
- Razer анонсировала Project Ava, игровой второй пилот на базе искусственного интеллекта, предназначенный для обучения в игре и анализа производительности.
- Project Ava предлагает советы и игровые стратегии в режиме реального времени, а также персонализированные тренерские советы и анализ игрового процесса.
- Компания еще не назвала конкретную дату запуска общедоступной версии Project Ava, но сегодня начинается регистрация бета-версии.
На выставке CES 2025 компания Razer представила Project Ava — игрового помощника на базе искусственного интеллекта, созданного для улучшения ваших игровых впечатлений. Этот инновационный инструмент выполняет функции наставника по киберспорту, стратегического советника и технического помощника, стремясь помочь вам добиться успеха в видеоиграх.
"Просто покупай индекс", говорили они. "Это надежно". Здесь мы обсуждаем, почему это не всегда так, и как жить с вечно красным портфелем.
Поверить в рынокRazer представляет Project Ava как идеального компаньона для геймеров. Этот искусственный интеллект предназначен для мгновенного предоставления рекомендаций, основанных на опыте профессионального геймера. Он действует как цифровой наставник, не только оценивая ваши действия в игре, но и предлагая улучшения после завершения игры.
Не пробуя лично Ava, мы видели предоставленные Razer скриншоты, демонстрирующие, что Ava наблюдает за полем боя в режиме наблюдателя, определяя движения и покупки противника. Его послеигровой анализ идет еще дальше, высоко оценивая эффективные сборки предметов и подчеркивая слабые места в управлении картой. Подобная информация потенциально может принести пользу как новым игрокам, стремящимся повысить свой рейтинг, так и опытным игрокам, стремящимся усовершенствовать свои стратегии.
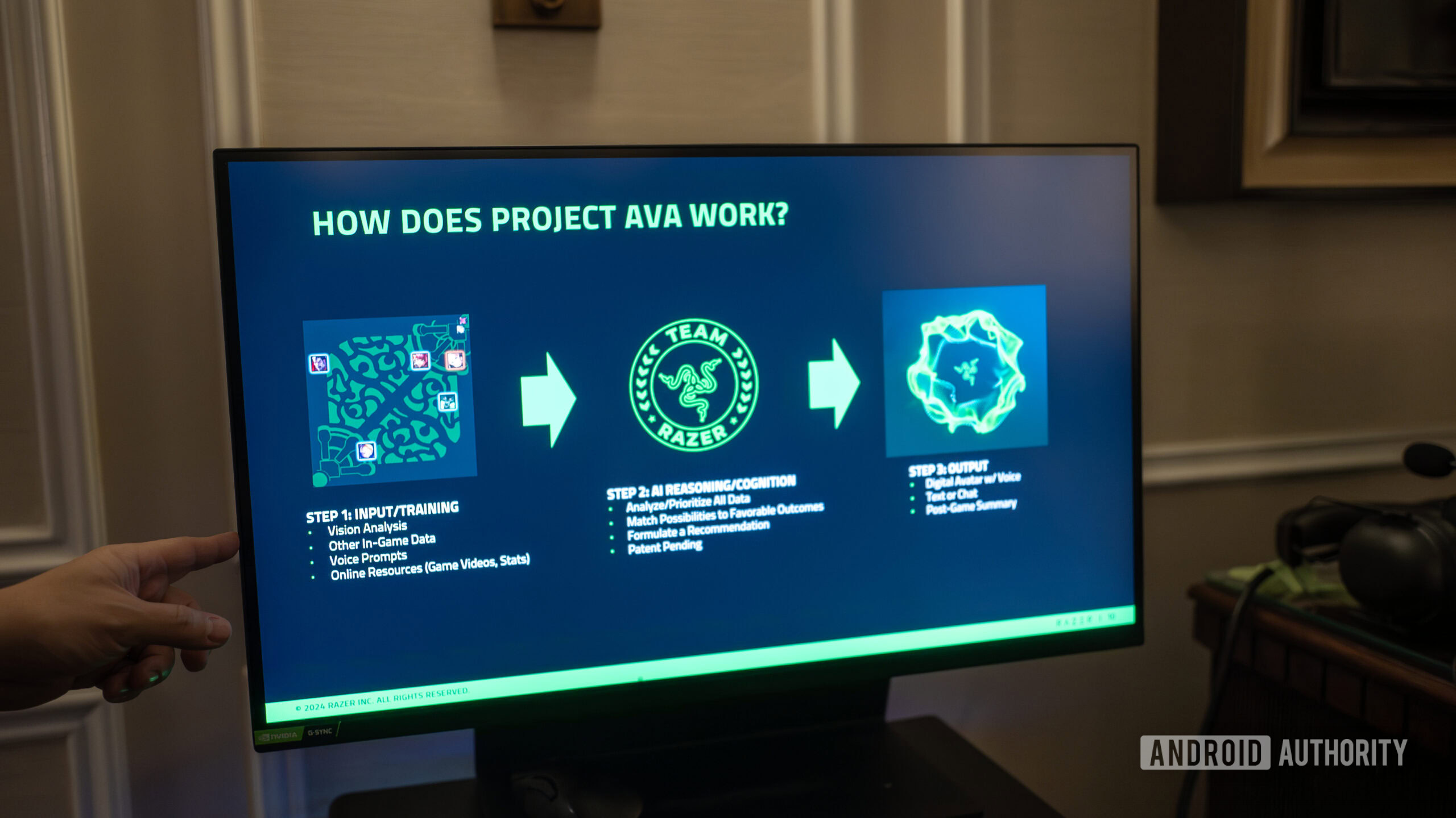

Razer подчеркивает, что Ава способна выступать в роли внутриигрового тактика. Независимо от того, решаете ли вы сложную головоломку или нуждаетесь в совете, как победить сильного противника, Ava обращается к коллективным знаниям и игровым ресурсам, чтобы предлагать полезные советы, не требуя от игроков паузы или отключения от игры. Игроки могут вызывать Аву, используя методы, которые им подходят лучше всего — с помощью голосовых команд, окон чата или плавающих окон.
Как исследователь, участвующий в Project Ava, я хотел бы выделить еще один аспект этого проекта, который делает его поистине уникальным — он не только улучшает игровой процесс, но и оптимизирует производительность системы. Одна из его выдающихся функций позволяет регулировать настройки оборудования простым нажатием кнопки. Это включает в себя увеличение частоты кадров, сокращение времени загрузки, сканирование обновлений программного обеспечения и поддержание максимальной эффективности вашей установки, гарантируя ее максимальную производительность.
Когда проект Ava будет доступен?
Хотя компания пока не раскрыла никаких конкретных планов по ее публичному обнародованию, сегодня была запущена регистрация на публичную бета-версию. Кроме того, мы получили возможность взглянуть на то, как Project Ava работает в реальности, с помощью тизер-видео. Голос Авы явно роботизирован, предлагая футуристическую, но иногда тревожную атмосферу. Тем не менее, рекомендации, предоставляемые во время игры, кажутся полезными, хотя они больше ориентированы на общие напоминания, чем на конкретные тактики в реальном времени. Например, вместо «Увернись от этого навыка сейчас!» вы можете получить «Будьте внимательны к ротации».
В прошлом году NVIDIA представила G-Assist — ИИ-помощник, предназначенный для игровых помощников с сопоставимыми функциями. Учитывая, что выдающиеся деятели игровой индустрии используют игровые инструменты на основе искусственного интеллекта, очевидно, что эта тенденция усиливается. Однако, как и в случае с любой новой технологией, здесь есть неопределенности. Смогут ли такие платформы, как Ava и G-Assist, сделать игры более доступными или они превратят соревновательные матчи в зрелища между ИИ и ИИ? Будет интересно наблюдать за влиянием этих консультантов по искусственному интеллекту на небольшую индустрию игровых гидов.
Смотрите также
- Лучшие телефоны Android для студентов 2024 года
- Coros против Garmin против фитнес-теста Polar: сравнение нового Vertix 2S с Forerunner 965 и Vantage V3
- 10 лучших чехлов, которые обязательно нужно иметь для вашего нового Samsung Galaxy S25 Ultra!
- ANBERNIC только что опубликовал видео о RG VITA Pro, и это зверь с двойной ОС.
- Нечестивцам нет покоя: каждое легендарное оружие и как его получить
- Лучшие защитные пленки для экрана Motorola Razr 2024 2024 года
- Используйте эти коды в Element Battles, чтобы получить бесплатные деньги.
- Готовы к удивительной классике научной фантастики? Поклонники выбрали 10 лучших научно-фантастических фильмов всех времен, и список просто эпичен!
- Pixel 9 Pro Fold — это тот телефон, который я хочу носить без чехла… и тот, который мне не следует носить
- Проблема решена? Утечка сообщает, что ремонтопригодность батареи Pixel 11 Pro Fold может быть улучшена.
2025-01-07 17:18