
Tldr
- Пользователь Reddit создал ярлык iOS, который отображает грубо вычисленное предполагаемое время зарядки для iPhone.
- Шорткет использует простой расчет на основе текущего уровня батареи. Несмотря на то, что он не идеален, он предлагает обходной путь, так как iOS не хватает этой функции изначально.
- Телефоны Android, такие как Google Pixel Lineup Display Основное время зарядки прямо на экране блокировки.
По сути, платформы Android и iOS достигли зрелости, что привело к тому, что они черпают вдохновение друг с другом, поскольку они рассматривают будущие события. Например, Apple Incorporated Elements настройки домашнего экрана, увиденные в Android в iOS 18, в то время как Google собирается представить функцию обновлений в прямом эфире, напоминающую iOS с Android 16. Однако удивительно, что пользователи iPhone еще не наслаждаются функцией, доступной на Android Телефоны. Ориентировочное время осталось для полной зарядки. Это упущение разочаровало многих пользователей iPhone, что предлагает одному пользователю создать импровизированное решение с помощью приложения ярлыков.
"Просто покупай индекс", говорили они. "Это надежно". Здесь мы обсуждаем, почему это не всегда так, и как жить с вечно красным портфелем.
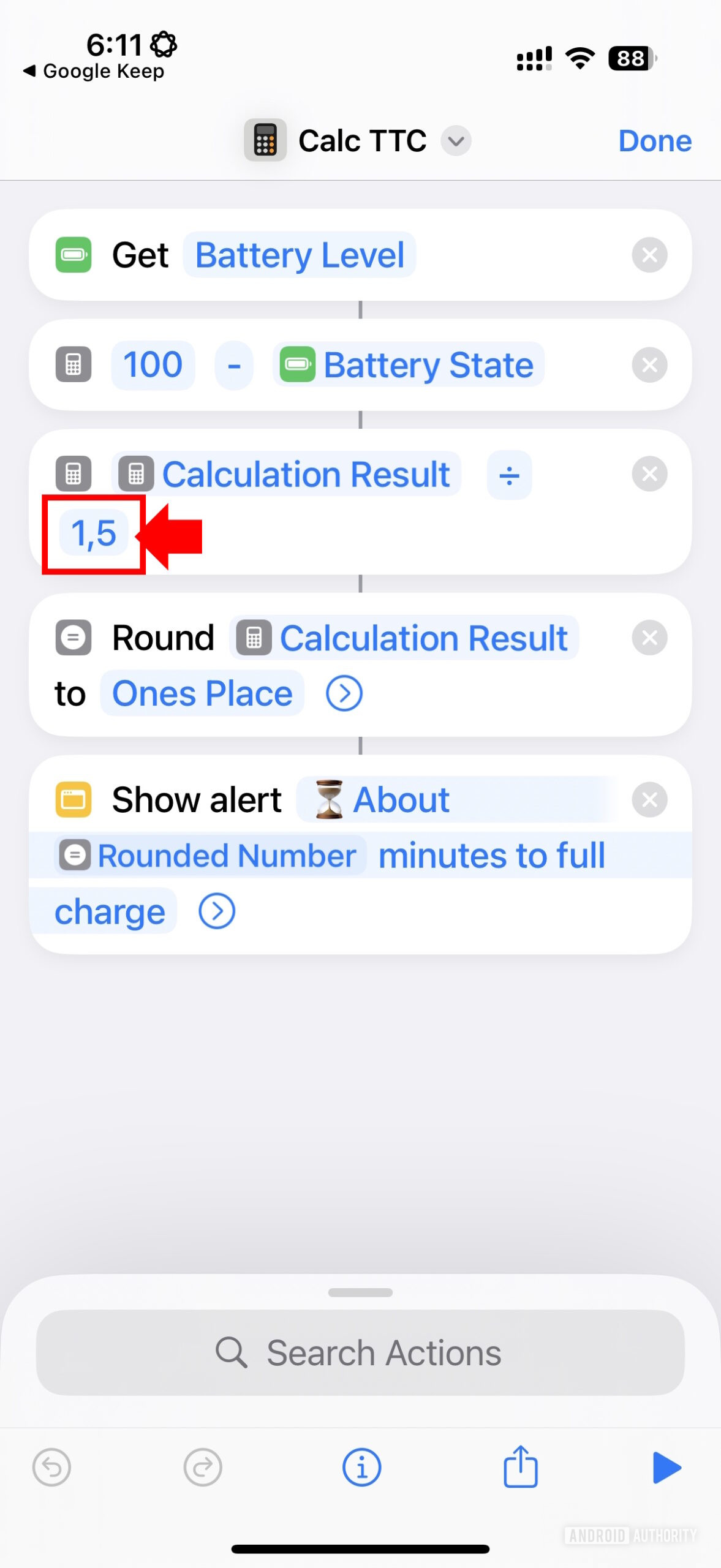
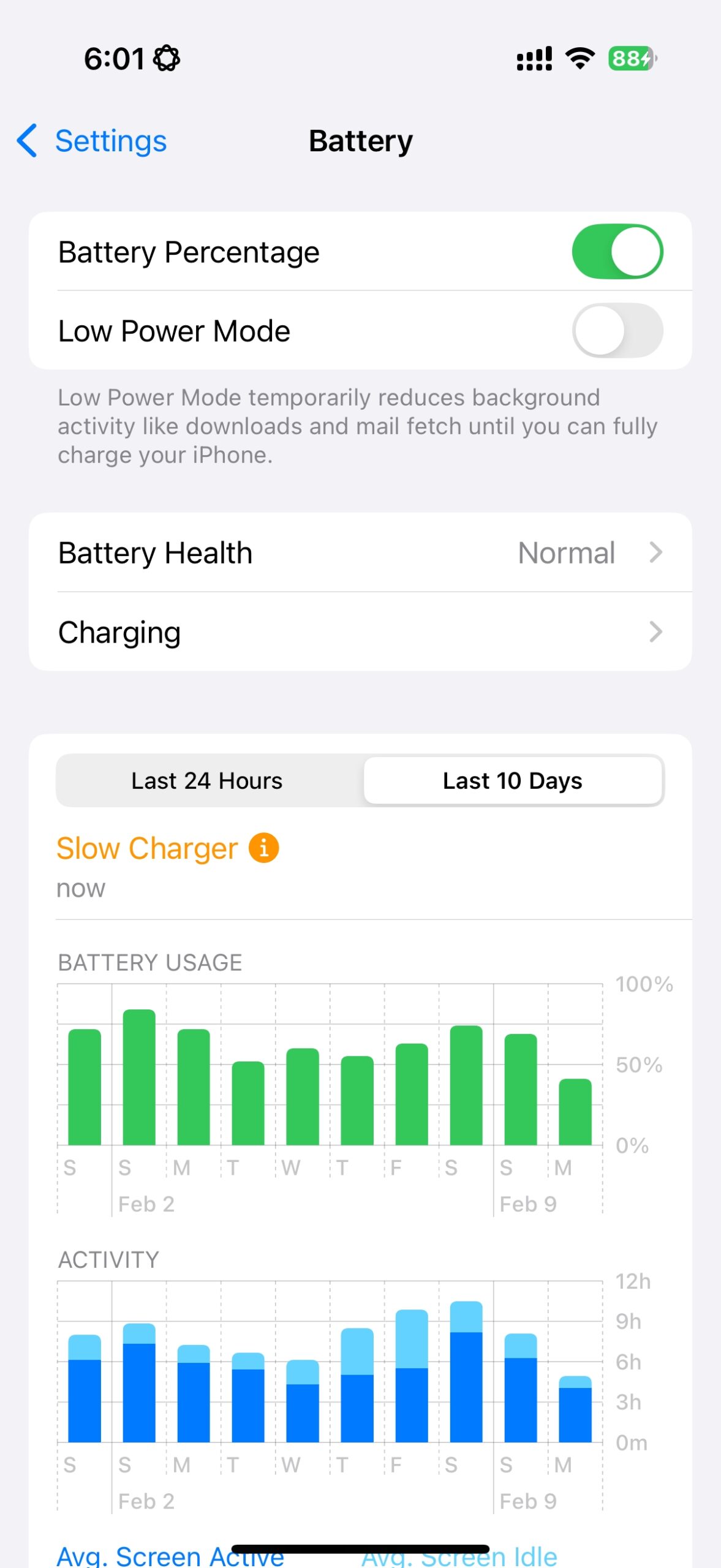
Поверить в рынокПользователь Reddit Alxr25 разработал простое предупреждение «оставшегося времени зарядки» для iPhone с помощью приложения ярлыков. Этот ярлык по существу рассчитывает, сколько минут осталось до полного заряда, вычитая текущий уровень батареи от 100, а затем делясь на это число на 1,5, округлив его и показывая результат в качестве предполагаемого времени за считанные минуты, необходимые для зарядки.
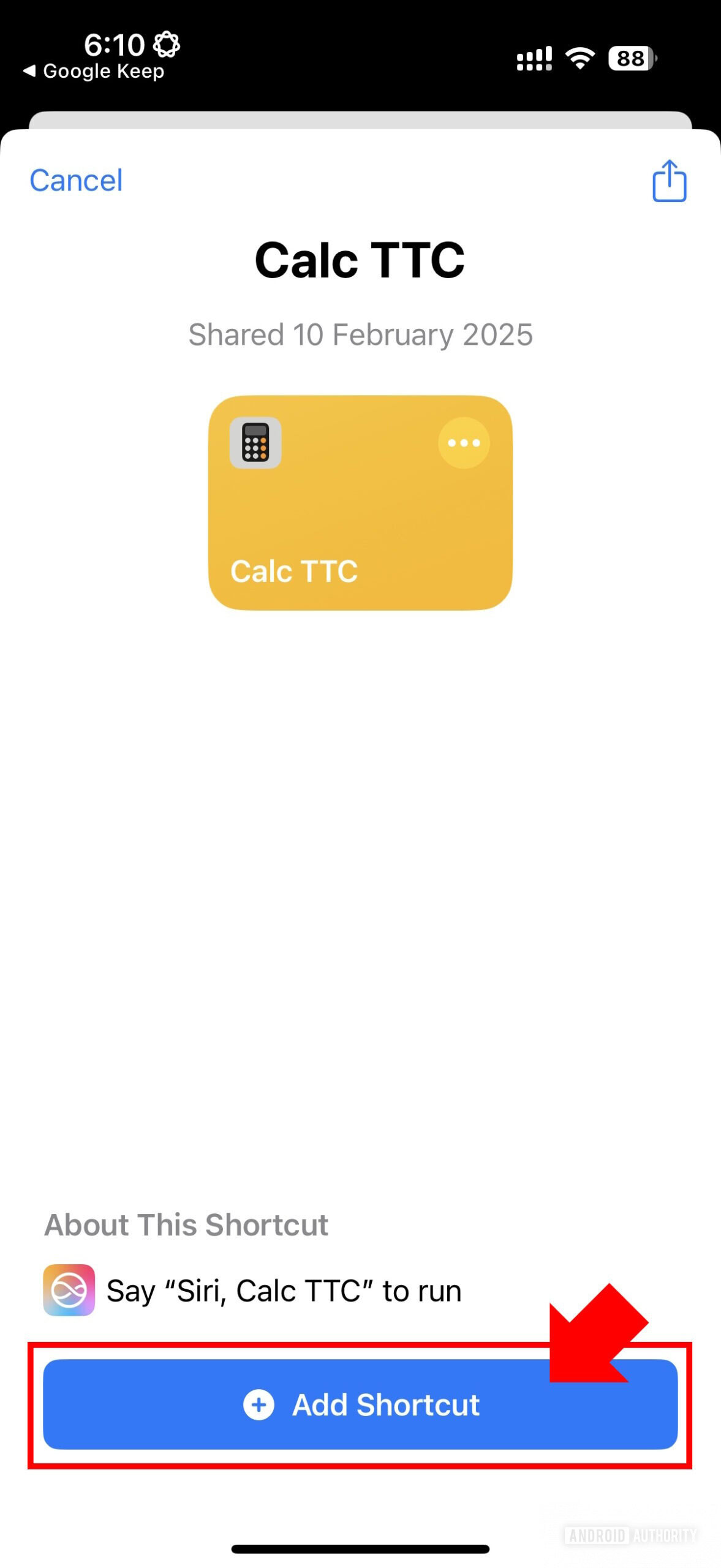
Чтобы настроить ярлык на вашем устройстве, загрузите его по предоставленной ссылке iCloud Sharing. Если в ярлыке появляется число «1,5», обязательно измените его на «1,5» для совместимости с десятичной системой вашего локали, или вы можете вместо этого использовать эту предварительно отредактированную версию ярлыка.
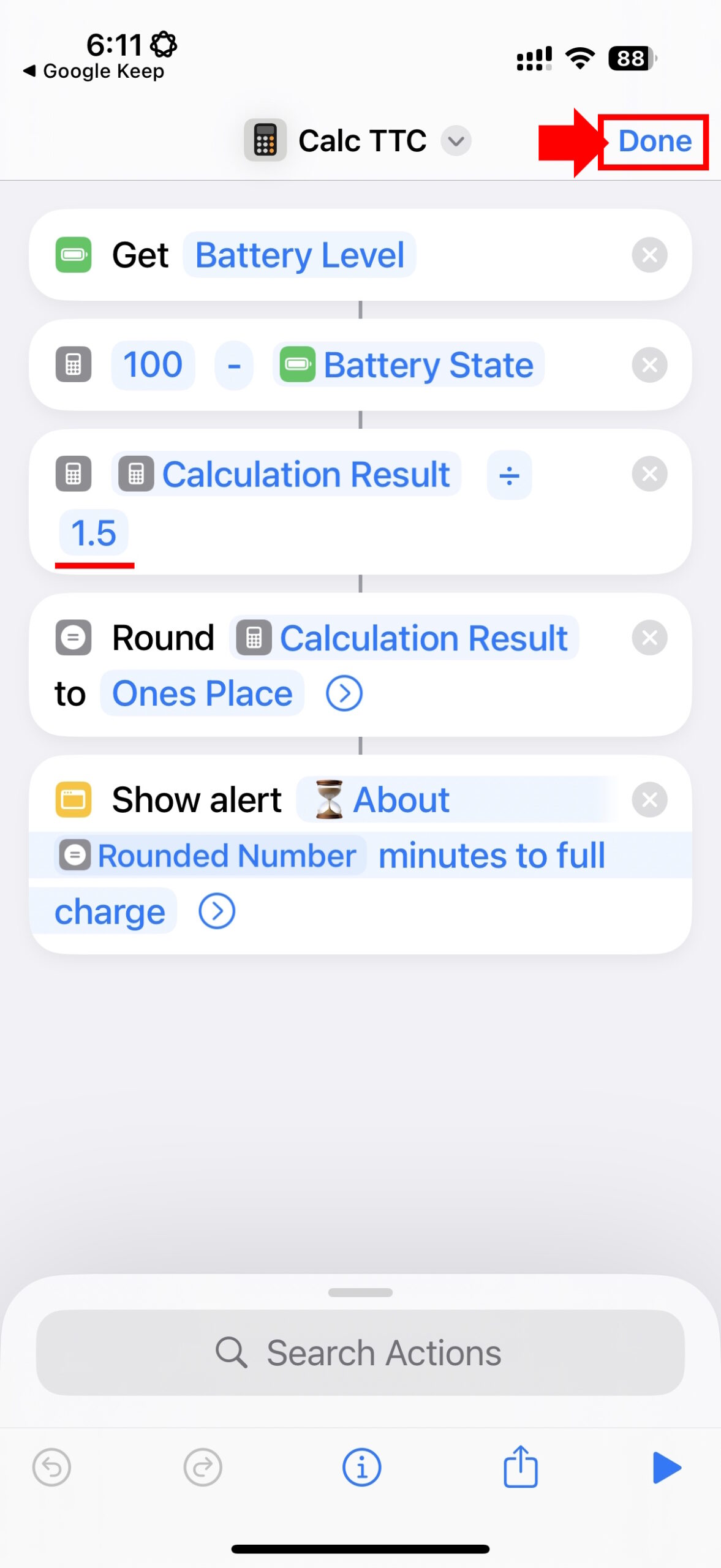
Установив ярлык, пользователь дополнительно настроил автоматизацию для запуска ярлыка всякий раз, когда их iPhone подключен к зарядному устройству. Это означает, что вы получите оценку времени зарядки мгновенно при подключении.

Пользователь рассчитал значение «1,5» для деления на основе их наблюдения, что iPhone 15 заряжается со скоростью 1% каждые 1,2 минуты в диапазоне зарядки 0-50% и 1% каждые 1,8 минуты в диапазоне 50-100%. Чтобы найти среднюю скорость заряда, они получили среднее значение этих двух значений (среднее значение между 1,2 и 1,8 составляет 1,5).
Безусловно, эта оценка довольно простая и не всегда может быть точной из -за таких факторов, как тип используемого телефона и зарядного устройства, окружающая температура, температура iPhone во время зарядки, любые ограничения батареи, состояние самого аккумулятора и Активные функции адаптивной зарядки. Другими словами, существует множество переменных, влияющих на время зарядки для iPhone, поэтому одно число не может полностью отразить ситуацию.
Время, необходимое для последних 10% заряда аккумулятора вашего iPhone, может варьироваться от периодов, таких как 70-80% и 80-90%, поскольку процесс зарядки значительно замедляется, когда вы приближаетесь к 100%. Следовательно, может быть сложно точно предсказать точно, сколько еще минут требуется для iPhone, чтобы закончить зарядку.
Трудно поверить, что устройства iOS по сей день не предлагают точную оценку времени зарядки. На телефонах Android, таких как My Pixel 9 Pro XL, вы можете узнать, сколько времени потребуется, чтобы батарея была полностью заряжена, все отображаются прямо на экране блокировки.


Если устройство Android не обеспечивает предполагаемого времени зарядки, оно все равно будет отображаться, проходит ли ваш телефон быстро зарядиться или регулярно зарядка непосредственно на экране блокировки. И наоборот, iPhone не предлагают этого удобства и требуют, чтобы вы перемещались в настройки & gt; Батарея , чтобы определить, используете ли вы быструю зарядку или стандартную зарядку.
На iPhone нет встроенного «полностью заряженного» предупреждения. Вместо этого я установил индивидуальное уведомление о сочетаниях на своих Apple Watch, чтобы вибрировать, когда мой iPhone 16 Pro достиг 100% -ного уровня заряда.
Таким образом, у iOS есть широкие возможности для улучшения того, как он информирует пользователей об их статусе зарядки, и я надеюсь, что они считают Android источником вдохновения в этой области. На данный момент, вот быстрый обходной путь, использующий этот ярлык, чтобы получить приблизительное чтение.
Смотрите также
- YouTube дает сбой — что делать, если в вашей ленте застрял NaN:NaN
- Шон Дидди Комбс (56) — дело снова в центре внимания, поскольку апелляционный суд ставит под сомнение приговор.
- Fitbit облегчает понимание вашего уровня кардиофитнеса, но пока не для всех.
- Поддерживает ли Samsung Galaxy S24 FE eSIM и две SIM-карты?
- Я не знал, насколько мне нужны запланированные действия Gemini, пока не попробовал их.
- Я попробовал Oxygen OS 15, и вот что у OnePlus получилось правильно (а что нет)
- Создатель ‘Fullmetal Alchemist’ представляет новый аниме с трейлером и примерным сроком выхода.
- Все фильмы, выходящие на Hulu в апреле 2026 года.
- Лучшее время для обмена фунтов на дирхамы — прогноз, которому можно верить
- 30 лучших фильмов об обмене парой и женой, которые вам нужно посмотреть
2025-02-10 18:18