
Новый ИИ-консультант Google по здоровью использует ‘смеситель Gemini’, чтобы объединить данные о вашей физической форме, сне и общем состоянии здоровья, в результате чего формируются индивидуальные рекомендации по тренировкам. В октябре владельцы Pixel Watch 4 и часов Fitbit получат возможность протестировать его. Однако это поднимает вопрос, который меня давно волнует относительно Google: почему следующее поколение Pixel и Fitbit не могут существовать вместе?
"Просто покупай индекс", говорили они. "Это надежно". Здесь мы обсуждаем, почему это не всегда так, и как жить с вечно красным портфелем.
Поверить в рынокПосле выпуска Pixel Watch 3, Engadget спросил у Google, появится ли когда-нибудь «умные часы под брендом Fitbit». Google ответила, заявив, что Pixel Watch представляют собой будущее направление развития умных часов Fitbit. Компания также упомянула, что разработка аппаратного обеспечения Fitbit в будущем будет направлена на создание минималистичных и долговечных фитнес-трекеров, таких как Inspire 3.
Вы все еще можете приобрести новейшие модели Fitbit Sense 2 или Versa 4, которые позволяют делиться данными о частоте сердечных сокращений, сне, уровне стресса и кардионагрузке с продвинутым искусственным интеллектом Fitbit. По словам представителя Google, эти новейшие устройства Fitbit предоставляют наиболее полные данные для использования их персональными тренерами по здоровью.
Представитель компании не комментировал, смогут ли более старые устройства Fitbit обеспечить полноценный опыт коучинга. Хотя Pixel Watch 4 может похвастаться более точными данными благодаря GPS с двумя диапазонами и продвинутыми алгоритмами отслеживания сердечного ритма и сна, только последние модели Pixel Watch могут синхронизировать персонализированные тренировки от ИИ-тренера непосредственно на ваше запястье для удобного доступа.
Google, несомненно, имеет право рекламировать свои Pixel Watches как предлагающие лучший опыт умных часов для спортсменов. Однако я считаю, что такая стратегия может упустить из виду множество людей, которые ценят тренерские услуги Fitbit, но предпочитают традиционный дизайн часов Fitbit.
Почему ИИ-тренер от Fitbit звучит так заманчиво
После того, как вы поделитесь своими целями в области фитнеса с ИИ Fitbit, вы можете рассчитывать на персонализированные графики тренировок с еженедельными этапами. Эти планы разработаны специально для соответствия вашим индивидуальным целям в области фитнеса и физической форме. Планы адаптируются динамически, учитывая такие переменные, как качество сна, сердечно-сосудистая нагрузка и другие соответствующие факторы.
Кроме того, Gemini предлагает индивидуальные рекомендации по таким темам, как сон, физические упражнения и здоровье, анализируя ваши привычки, а не предоставляя общие ответы, характерные для большинства чат-ботов, связанных с фитнесом.
Самым удобным способом можно легко сообщить, что вы не в лучшей форме или плохо себя чувствуете, и искусственный интеллект адаптирует ваше расписание тренировок, например, заменив час высокоинтенсивных интервальных тренировок на 30 минут йоги из-за накопившегося недосыпа.
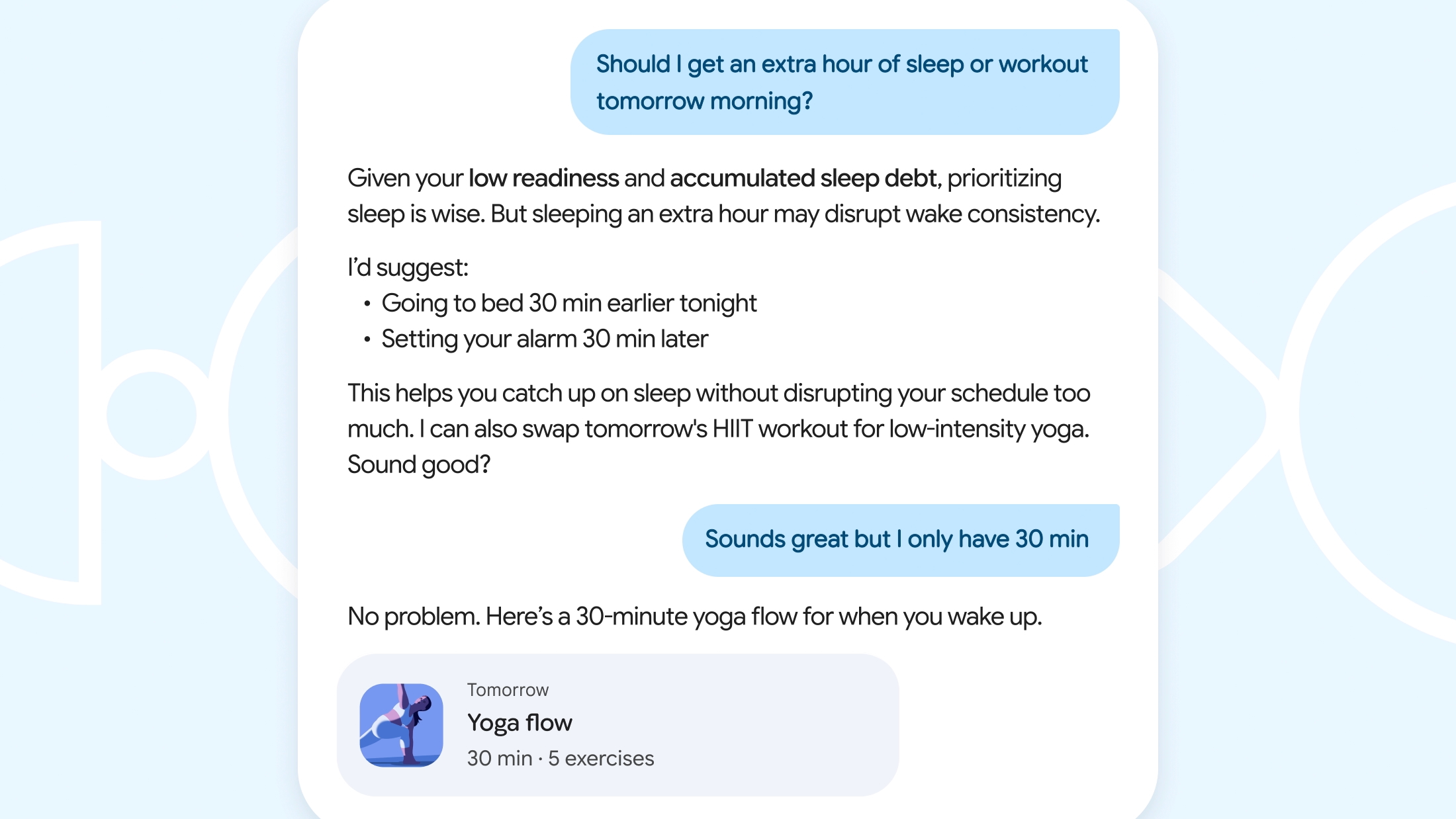
Уникальные умные часы, предлагающие индивидуальные рекомендации по тренировкам, встречаются на рынке нечасто. В то время как часы Garmin предоставляют ежедневные рекомендованные упражнения и адаптированные программы обучения, то, что может выделить Fitbit, — это их мониторинг в реальном времени, корректировки и обновления.
Устройство Garmin Forerunner 970 способно настраивать рекомендации по тренировкам на основе уровня вашей сердечно-сосудистой и мышечной нагрузки. Однако важно отметить, что его алгоритм не предназначен для выявления состояний, таких как болезнь, травма или беременность, которые могут повлиять на вашу способность следовать предложенному плану. Кроме того, вам может быть сложно изменить конкретную тренировку, если ваш график станет загруженным.
Невероятно удобно, что я могу попросить устройство отслеживания физической активности перенести мою тренировку на пятницу и назначить легкую пробежку на сегодня, причем все обновления происходят мгновенно. Если эта функция будет работать, как заявлено, я считаю, что подписка оправдает себя, поскольку это демонстрирует динамичный подход к планированию занятий спортом.
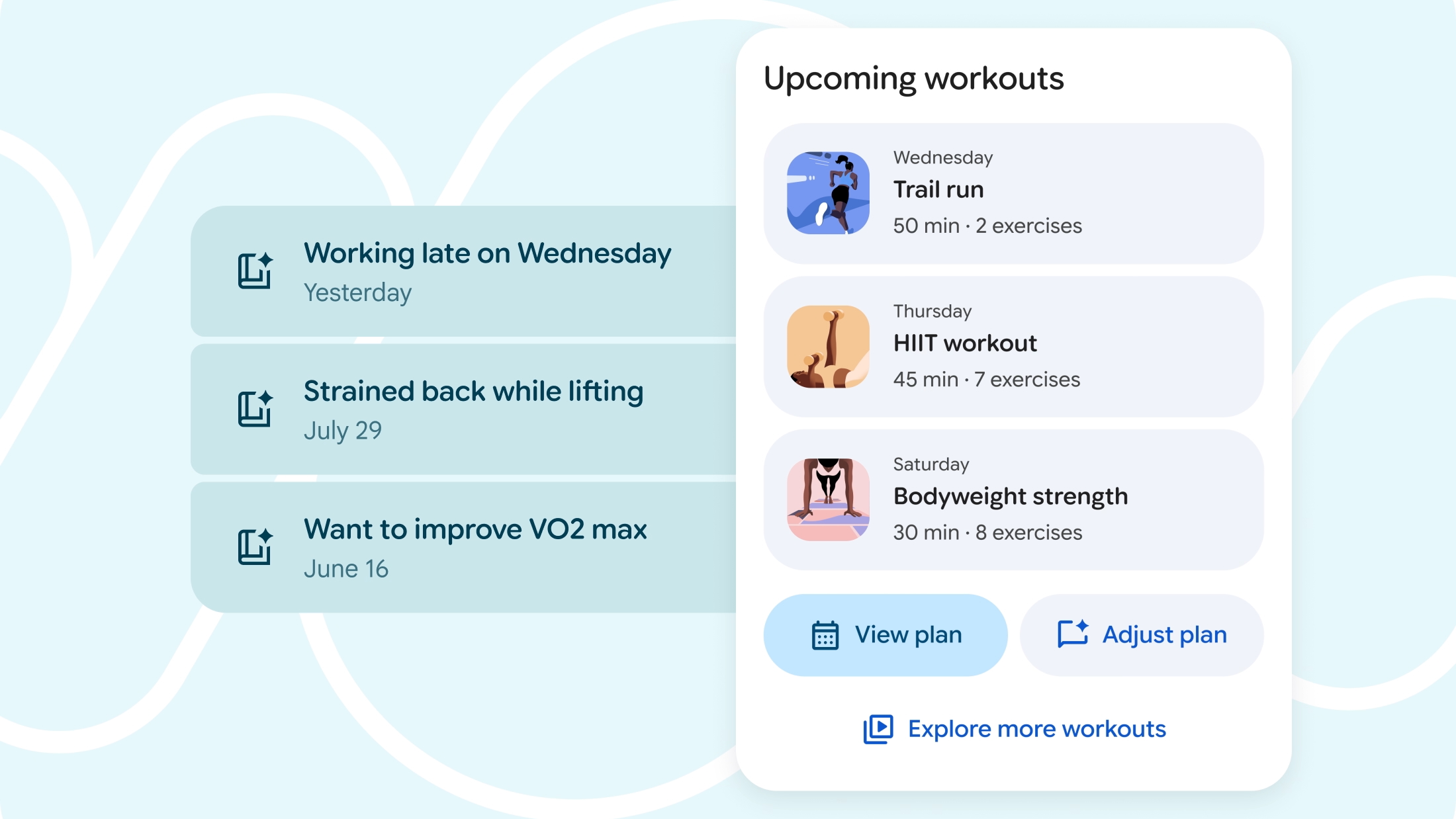
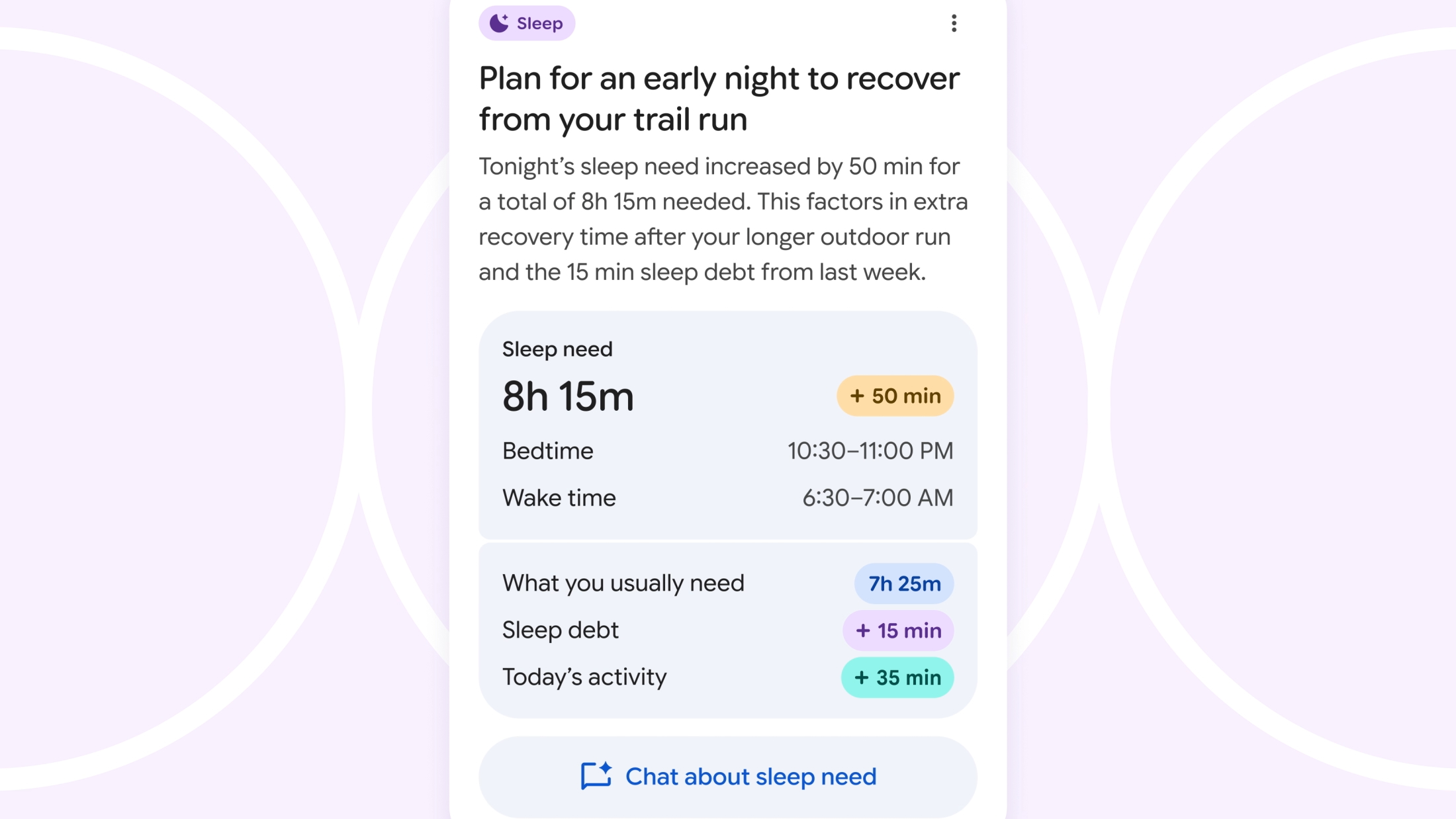
Искусственный интеллект от Google в сфере фитнеса не сталкивается со значительной конкуренцией со стороны заметных игроков, таких как Garmin Connect Plus и Strava. Хотя обе платформы могут включать ваши данные об упражнениях в сводки чат-ботов, им не хватает прямого способа взаимодействия с ними или легкого переключения на различные планы тренировок. Проще говоря, вы можете получить статистику из этих приложений, но не можете легко обсудить изменения в тренировках или переключиться на новые планы с ними, как это возможно с некоторыми другими фитнес-платформами.
По слухам, Samsung планирует выпустить AI-консультанта по здоровью в этом году, который позволит интегрировать данные о здоровье с ваших Galaxy Watch 8 и получать медицинские консультации от врачей для персонализированных рекомендаций по уходу за здоровьем, при поддержке чат-бота. В сравнении с этим, AI от Google, ориентированный на фитнес и оздоровление, имеет более скромные ожидания, что потенциально упрощает его внедрение.
Причина, по которой персональный тренер от Fitbit кажется довольно привлекательным, заключается в его потенциале, что, к сожалению, может привести к тому, что многие люди упустят возможность испытать его.
Некоторым людям просто не нужен ‘умный часы’.

Раньше я был ярым поклонником Fitbit, но времена меняются. Когда-то Fitbit лидировал в рейтингах рынка носимых устройств, но когда тенденции сместились в сторону умных часов и более доступных фитнес-браслетов, он начал терять свои позиции. В 2022 году Fitbit оказался на 10-м месте в списке продаж Counterpoint, что является значительным падением с 7-го места в 2021 году. В наши дни такие бренды, как Huawei, Xiaomi, Apple и Samsung, доминируют примерно над двумя третями рынка (по данным IDC), а Garmin удалось занять пятое место. Наступила новая эра для носимых устройств, и я теперь смотрю на этих новых гигантов в поисках следующего технологического решения для фитнеса!
Очевидно, что Fitbit может столкнуться с трудностями в конкуренции с этими глобальными брендами. Однако Garmin преуспевает в продаже дорогих часов, особенно спортсменам, благодаря своим продвинутым рекомендациям по тренировкам и часам с длительным временем автономной работы. Часы Fitbit предназначены для другой аудитории, но предлагают схожие преимущества.
Функция коучинга по здоровью, предлагаемая Fitbit, может получить распространение благодаря растущему принятию искусственного интеллекта, но она, вероятно, будет более привлекательна для любителей технологий, использующих iPhone или другие устройства Android, а не устройства Google Pixel. Эти пользователи могут посчитать отдельное устройство Fitbit более привлекательным по сравнению с тем, что связано с Pixel Watch.

Многие родственники со стороны моей большой семьи раньше использовали iPhone и устройства Fitbit, пока производство последних не прекратилось. Они бы оценили возможность взаимодействия с «умной Siri» для получения советов по снижению веса или программ тренировок для начинающих, но не готовы покупать новый телефон или крошечный браслет Fitbit Inspire ради этого, равно как и жертвовать неделей работы от батареи ради приложений.
Аналогично, многие члены моего местного бегового клуба предпочитают фитнес-часы, предназначенные для длительного использования. Хотя быстрая зарядка Pixel Watch 4 потенциально может перезарядить аккумулятор во время душа, остаётся неясным, готовы ли они пожертвовать уверенностью в большем запасе заряда батареи.
Если бы Google предложила модель, подобную Fitbit, будь то Sense 3 или Versa 5, оснащенную датчиками здоровья, улучшенной точностью GPS и функцией спутниковой SOS, а также хвасталась недельной продолжительностью работы от батареи, как случайные, так и преданные спортсмены с удовольствием обменяли бы преимущества Pixel Watch 4 на это. Такое предложение от Google могло бы значительно увеличить число подписчиков Fitbit Premium, обслуживая пользователей на платформах Android и iOS.
Учитывая маловероятность этого, давайте посмотрим, окажется ли успешной стратегия Google по созданию эксклюзивности для Pixel, привлекая больше спортсменов к использованию смартфонов Pixel для получения рекомендаций по тренировкам на основе искусственного интеллекта.
Смотрите также
- Первые 11 вещей, которые нужно сделать с Samsung Galaxy Watch Ultra
- Объяснение всех функций искусственного интеллекта в Gmail
- Вот почему вам, возможно, придётся подождать Android 17, чтобы использовать Motion Cues
- Я проводил время за готовкой с помощью Gemini Live. Это был кусок пирога?
- ‘Jujutsu Kaisen’ снова возглавляет список 10 самых просматриваемых аниме недели на Crunchyroll.
- Джереми Реннер называет свою любимую кинороль за всё время.
- Поддерживает ли Samsung Galaxy S24 FE eSIM и две SIM-карты?
- Лучшие телефоны для людей, чувствительных к ШИМ/мерцанию, 2024 г.
- «Лило и Стич» возглавили список самых просматриваемых фильмов на Disney+ на этой неделе: вот оставшаяся десятка лучших фильмов.
- Новая ошибка Pixel зависает на вашем телефоне после звонков, но вот как это исправить
2025-08-27 18:25