TLDR
- Многие из факторов ранжирования, задействованных в сверхсекретном алгоритме поиска Google, предположительно стали известны.
- Эта утечка проливает свет на то, как, по-видимому, работает поиск Google и какие атрибуты он использует для ранжирования контента на странице результатов поисковой системы.
- Однако выводы из просочившегося документа не согласуются с заявлениями Google по этим темам на протяжении многих лет.
В этом тексте обсуждается важность понимания того, как работает поисковый алгоритм Google, чтобы оптимизировать веб-сайты для лучшего рейтинга в поисковых системах. Автор упоминает, что, хотя Google предоставил рекомендации по созданию контента, ориентированного на людей, некоторые владельцы веб-сайтов сообщают о несоответствиях между этими рекомендациями и фактическими результатами поиска. Затем автор ссылается на просочившийся документ, который, судя по всему, противоречит некоторым публичным заявлениям Google о его алгоритме.
"Просто покупай индекс", говорили они. "Это надежно". Здесь мы обсуждаем, почему это не всегда так, и как жить с вечно красным портфелем.
Поверить в рынокДо крупных инвестиций Google в обзоры на основе искусственного интеллекта и персонализированный поиск компания в основном полагалась на предоставление результатов поиска через классический интерфейс поиска Google, с которым мы знакомы. Однако процесс генерации этих ответов за кулисами довольно сложен. Google всегда держал свою формулу ранжирования в поисковых системах в строжайшей коммерческой тайне, предпочитая вместо этого предоставлять веб-сайтам рекомендации, которым они должны следовать. Недавно ходили слухи об утечке, которая якобы раскрывает внутреннюю работу алгоритма поиска Google. Во многих аспектах эта утечка подчеркивает расхождения между рекомендуемыми лучшими практиками компании и фактическими факторами, которые она учитывает в результатах поиска.
Новость: алгоритм поиска Google якобы просочился
SparkToro утверждает, что получила доступ к более чем 2500 страницам документации Google Content API Warehouse.
В отчете упоминается, что документация случайно попала на GitHub в марте 2024 года, но затем была удалена. Однако вы можете найти копии v0.4.0 и v0.5.0 google_api_content_warehouse на Hexdocs (мы в Android Authority) не могут проверить подлинность этих просочившихся документов, поэтому читателю рекомендуется действовать по усмотрению).
Как технический энтузиаст, я бы описал это так: документация является важнейшим компонентом собственной формулы или алгоритма поиска Google. Он явно не раскрывает значение, которое система ранжирования Google придает различным функциям веб-сайта или его содержанию. Вместо этого он предоставляет информацию об информации, которую Google собирает с веб-сайтов и веб-страниц. Первоначально этот отчет работает в тандеме с iPullRank для тщательного изучения предполагаемых API.
Эта утечка дает беспрецедентный взгляд на внутреннюю работу Google Search, раскрывая информацию, которая на удивление противоречит большей части того, что Google ранее публиковал публично. Чтобы полностью понять эти расхождения, важно углубиться в скрытые механизмы поиска Google.
Предыстория: что происходит за кулисами, когда вы выполняете поиск в Google?
![]()
Когда вы выполняете поиск в Google, вам как пользователю это может показаться простым и безобидным действием. Однако за кулисами этот, казалось бы, безобидный поступок играет значительную роль в развитии огромной индустрии стоимостью в миллионы долларов. Чтобы по-настоящему понять влияние вашего запроса, важно вникнуть в тонкости того, что происходит, когда вы нажимаете кнопку поиска.
Основы: поисковые системы, сканирование веб-страниц, индексирование веб-страниц и ранжирование результатов поиска.
Конечно! Когда людям нужна информация из Интернета, они обращаются к сайту, называемому «поисковой системой». Они вводят свой запрос, чтобы поисковая система нашла соответствующие данные, и поисковая система выдает ответ, отвечающий на их вопрос. Очень просто!
С моей точки зрения как пользователя, я ценю обширную работу, которую поисковая система выполняет за кулисами. Однако для более четкого понимания давайте разобьем его функции на три основные задачи:
- Сканирование. Поисковая система должна знать все данные Интернета, чтобы выяснить, кто на что отвечает и где и что отвечает. Для этого поисковая система «сканирует» весь Интернет, то есть посещает каждый веб-сайт и веб-страницу.
- Индексирование. Страницы, которые посетил сканер, анализируются на предмет их данных и содержания, и эта информация сохраняется в легкодоступном виде.
- Рейтинг. Поскольку сотни и тысячи веб-сайтов пытаются ответить на один и тот же запрос, необходима система, которая показывает, кто первым представляется пользователю. Обычно это называют рейтинговой системой. Наиболее заметной формой этого является позиция, на которой веб-сайт появляется на странице результатов поисковой системы (SERP).
Как технический энтузиаст, я бы описал это так: лично я считаю, что сложная система ранжирования играет важную роль в определении порядка результатов поиска. Он выбирает, какие статьи появляются в самом верху, кто попадает на первую страницу и даже какие конкретные комбинации ключевых слов приводят к отображению определенных статей.
Почему рейтинг имеет значение в Google Search или любой поисковой системе?
Поиск Google, являющийся наиболее широко используемой поисковой системой в мире, обрабатывает огромный объем поисковых запросов каждый день или неделю. Если вы подсчитаете количество запросов, которые вы выполняете лично, и умножите его на миллиарды интернет-пользователей по всему миру, вы почувствуете его огромное влияние. Google действует как управляющий трафиком в Интернете, способный при правильном подходе направлять колоссальные объемы веб-трафика к вашему цифровому пункту назначения.
У предприятий есть огромная возможность получить значительный доход, когда они занимают первое место на хорошо посещаемой странице результатов поисковой системы (SERP). Большая часть пользователей склонна нажимать на первоначальный результат, при этом количество кликов резко уменьшается по мере продвижения вниз по списку.
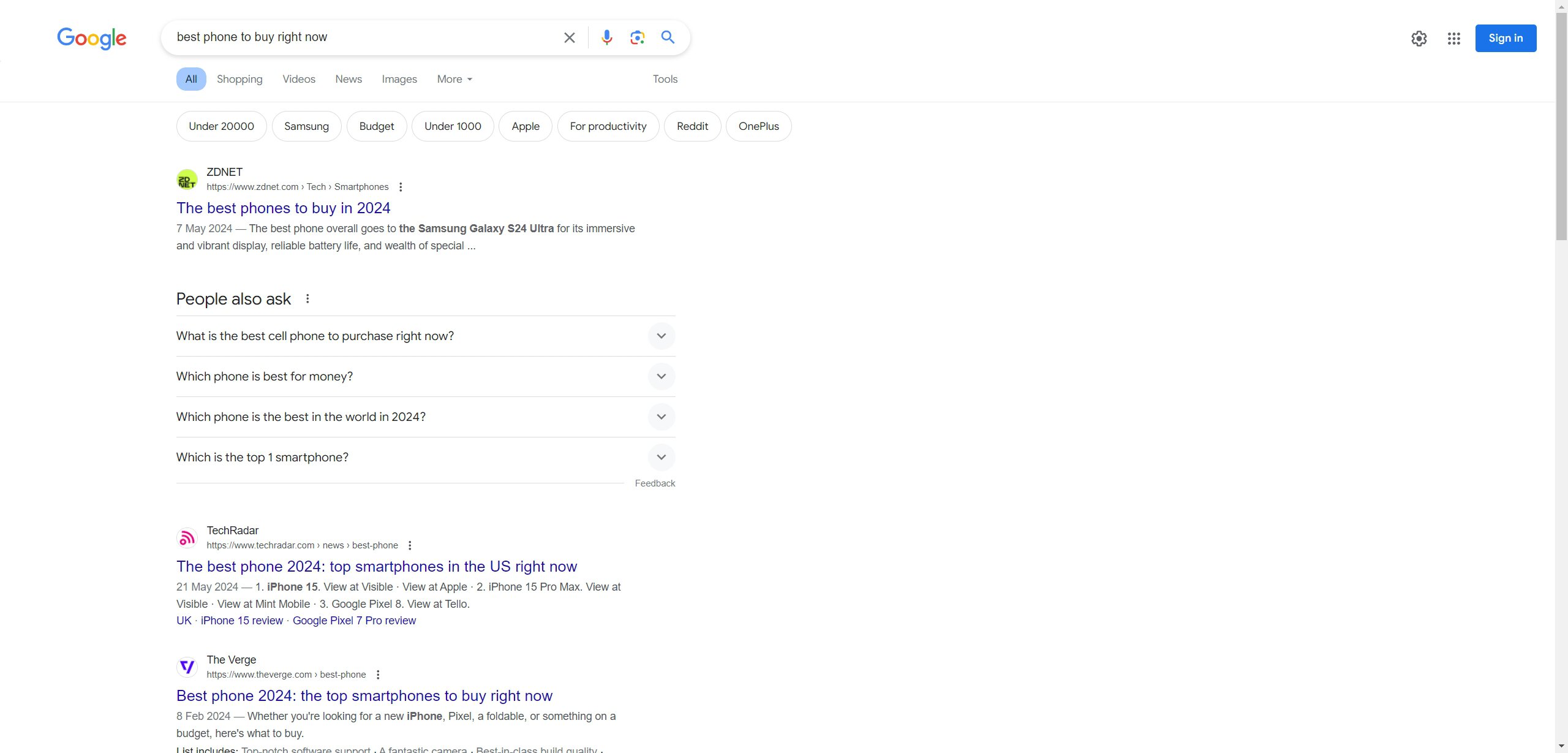
Вы недавно нажимали на второй, третий, четвертый или пятый результат поиска в Google? Обычно это происходит, когда верхний результат не соответствует вашим потребностям, и вам часто приходится пересматривать свой поисковый запрос, прежде чем полностью изучить параметры на начальной странице результатов поиска Google.
Помните ли вы последний раз, когда вы переходили на вторую страницу результатов поиска Google? На самом деле вы, вероятно, не сможете, поскольку Google заменил нумерацию страниц функцией бесконечной прокрутки для поиска. Однако большинство пользователей редко выходят за рамки первоначального набора ответов. Они либо находят то, что искали, либо корректируют свой запрос.
Секретный соус Google: алгоритм поиска Google
Итак, существует большое давление, чтобы все сделать правильно. Но как поступить правильно?
Стоит изучить, как работает система ранжирования Google, также известная как алгоритм поиска Google. Понимая его требования, веб-сайты могут соответствующим образом оптимизировать свой контент. Это может привести к стабильно высоким позициям в результатах поиска, привлечению миллиардов просмотров и получению значительного дохода.
Тем не менее, проблема остается неизменной: люди знают, что результаты поиска Google существенно влияют на рекламные и партнерские доходы, что приводит к существенной мотивации манипулировать результатами, потенциально ставя под угрозу пользовательский опыт.
Раньше я, как и многие другие, в значительной степени полагался на Поиск Google как на свой инструмент для поиска новой информации в Интернете. Подход Google, каким бы он ни был, доказал свою эффективность.
Публичный рецепт Google: рекомендации E-E-A-T для контента, ориентированного на людей
Google не раскрывает свою секретную формулу напрямую, а вместо этого предоставляет общедоступный набор инструкций по созданию контента, похожий на рецепт, который такие сайты, как мой, могут использовать в качестве руководства при создании собственного контента.
Как преданный поклонник SEO (поисковая оптимизация), я не могу не подчеркнуть важность, которую Google придает созданию «контента, ориентированного на людей». За прошедшие годы к этой концепции было добавлено бесчисленное множество слоев. Однако Google настоятельно рекомендует нам уделять первоочередное внимание созданию контента, который будет интересен пользователям превыше всего.
Google проповедует создание контента для людей, а не для поисковых систем. По понятным причинам отрасль работает иначе.
Идея заключается в том, что соблюдение принципов EEAT (экспертиза, авторитетность, надежность и полезность) повышает вероятность того, что поиск Google признает ваш контент ценным и соответственно повысит его рейтинг. Хотя это и не гарантированный метод, он представляет собой наиболее эффективный подход.
Проблема: то, что говорит Google, не соответствует тому, что, по-видимому, делает Google.
Будучи преданным последователем тенденций SEO и страстным сторонником эффективной оптимизации веб-сайтов, я заметил общую обеспокоенность среди владельцев сайтов: их трафик не восстановился, несмотря на соблюдение правил содержания Google EEAT. Чтобы уточнить, это принципы, которые отдают приоритет пользовательскому опыту и высококачественному контенту. Однако важно отметить, что представители Google публично поделились своим мнением по этому поводу. Они пролили свет на то, на чем они сосредоточены, и предложили владельцам веб-сайтов предложения по улучшению их стратегий.
Предполагаемая утечка информации об алгоритме поиска Google не соответствует заявленным рекомендациям Google и их предыдущим публичным комментариям по этому поводу.
iPullRank говорит следующее:
Слово «солгало» звучит грубо, но это единственное верное слово, которое можно здесь использовать. Хотя я не обязательно виню представителей Google за защиту своей частной информации, я не согласен с их попытками активно дискредитировать людей в мире маркетинга, технологий и журналистики, которые представили воспроизводимые открытия.
Основываясь на моей первоначальной оценке с использованием таких инструментов, как iPullRank и SparkToro, похоже, что предполагаемая утечка алгоритма противоречит заявленным намерениям Google.
- Авторитет домена. Google утверждает, что не использует концепцию «общего авторитета домена» в масштабе всего сайта для ранжирования результатов поиска, но просочившиеся документы предполагают, что Google вычисляет характеристику, называемую «авторитет сайта».
- Использование данных Chrome для ранжирования. Компания Google заявила, что не использует данные Google Chrome в рамках органического поиска. Утечка документов включает в себя несколько атрибутов измерения, связанных с Chrome.
- Клики: Представители Google Search отрицают использование кликов непосредственно в рейтинге поисковой выдачи, но существует множество доказательств, даже помимо утечки, что они действительно используют их в качестве меры успеха. Документы раскрывают то же самое: у Google действительно есть система «сигналов о кликах и показах», которая дополнительно включает в себя такие факторы, как «дата последнего хорошего клика», и измеряет результаты, у которых был «самый длинный клик во время сеанса», и многое другое.
- Новая «песочница» веб-сайта. Google утверждает, что не существует «песочницы», в которой веб-сайты разделялись бы по возрасту или отсутствию сигналов доверия. Утечка документов включает атрибут под названием «hostAge», который используется специально для «изолирования свежего спама во время обслуживания».
- Авторы: Google утверждает, что имена авторов должны быть доступны для читателей, а не для Google, поскольку они не влияют на рейтинг в поисковой выдаче. Утечка документов указывает на то, что Google, по крайней мере, собирал данные об авторах на страницах, хотя и не подтвердил, является ли это показателем ранжирования.
Как сторонний наблюдатель, я могу понять, почему Google предпочитает не раскрывать конкретные детали своего алгоритма поиска. Однако их склонность вводить в заблуждение вместо того, чтобы прямо отказываться комментировать определенные вопросы, может создать путаницу и неуверенность.
Другие важные выводы из просочившихся документов включают в себя:
- Свежесть имеет значение. Google учитывает даты в авторских строках, URL-адресах и т. д.
- Ссылки имеют значение. Google обращает внимание на привязку ссылок, их релевантность и разнообразие.
- Брендинг имеет значение. Брендинг имеет значение, выходящее за рамки экосистемы Google.
- История изменений имеет значение. Google хранит копию каждой версии каждой страницы, которая когда-либо индексировалась. Однако используются только последние 20 изменений.
- Понижение рейтинга. Содержание можно понизить по рейтингу по таким причинам, как ссылки, не соответствующие целевому сайту, порно и т. д.
Утечка документов огромна, и в ближайшие недели они будут тщательно проанализированы специалистами по SEO и контенту. Последуют многочисленные исследования, проливающие свет на алгоритмы поиска Google и стратегии оптимизации веб-сайтов для улучшения рейтинга в поисковой выдаче. Получение понимания работы Google Поиска полезно, но я признаю, что недостаточное понимание может иметь свои недостатки.
Как любопытный наблюдатель и страстный поклонник технологий, я должен признать, что последние просочившиеся документы предлагают интригующую информацию об алгоритмах поиска Google. Однако важно сохранять здоровую дозу скептицизма в отношении того, что нам официально говорят представители компаний. Эти документы еще не проверены Google, что заставляет нас сомневаться в их подлинности и значении для тщательно охраняемых секретов поискового гиганта.
Смотрите также
- YouTube дает сбой — что делать, если в вашей ленте застрял NaN:NaN
- Шон Дидди Комбс (56) — дело снова в центре внимания, поскольку апелляционный суд ставит под сомнение приговор.
- Создатель ‘Fullmetal Alchemist’ представляет новый аниме с трейлером и примерным сроком выхода.
- Fitbit облегчает понимание вашего уровня кардиофитнеса, но пока не для всех.
- Поддерживает ли Samsung Galaxy S24 FE eSIM и две SIM-карты?
- Я не знал, насколько мне нужны запланированные действия Gemini, пока не попробовал их.
- 30 лучших фильмов об обмене парой и женой, которые вам нужно посмотреть
- Все фильмы, выходящие на Hulu в апреле 2026 года.
- Я протестировал три разных дисплея, удобных для глаз, так что вам не придется
- 20 лучших рождественских ЛГБТ-фильмов всех времен
2024-05-29 11:26